Drycat
J'annonce le lancement officiel de Drycat.net !
Je me suis rendu compte à posteriori, que ce nom était utilisé par une marque d'aspirateurs industriels... Il est d'ailleurs assez peu parlant quant à sa finalité (du moins au premier abord). En effet, Drycat est site web permettant le partage de secret entre plusieurs personnes. Un secret (une phrase ou un fichier) va être découpé en plusieurs parties et, selon la configuration, il faudra réunir plus ou moins de parties pour arriver à reconstituer le secret original.
Exemple, avec un secret que l'on découpe en 4 parties, mais dont 3 seulement sont nécessaires pour le recomposer :
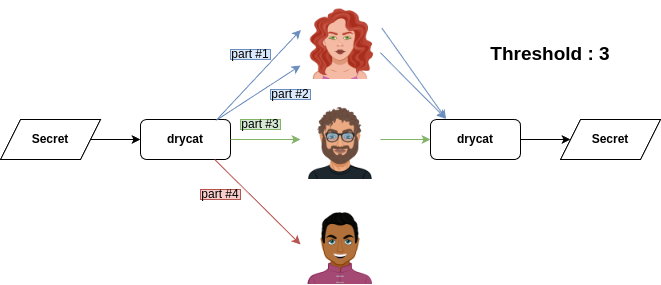
Ainsi, le partage de "pouvoir" est assez souple en fonction du nombre de parties générées et à qui on les affecte. Dans notre exemple, il faudra absolument que la première personne soit présente, mais elle ne pourra pas seule reconstituer le secret.
La théorie mathématique derrière Drycat fut décrite par Adi Shamir. Elle se base sur la reconstruction d'un polynôme d'ordre k (k étant le seuil) par interpolation. Bien qu'ancienne, elle reste pour autant très peu répandue, alors que je la trouve particulièrement intéressante. D'autant plus qu'Adi Shamir n'est autre qu'un des co créateurs du système RSA (système cryptographique asymétrique), utilisé un peu partout en informatique, notamment pour la couche de sécurité HTTPS.
Drycat se base sur l'implémentation JavaScript ouverte Amper5and, dont un site de démonstration est disponible ici. Alors, pourquoi avoir crée un site tiers supplémentaire ? Pour une question d'ergonomie et de facilité d'utilisation.
En effet, je voulais réaliser un site facile à utiliser par tout le monde, et surtout les personnes qui ne sont pas très techniques. La configuration nécessite de connaître quelque bases, mais avec Drycat, la récupération du secret est quasi automatique. Ainsi, les points forts sont :
- Ergonomie qui va à l'essentiel
- Utilisation des QRCode et de l'envoie par mail
- Recombinaison automatique du secret une fois que toutes les parties sont rentrées
- Chiffrement des fichiers réalisé directement depuis l'interface (mais en local sur l'ordinateur de l'utilisateur)
- Hébergement des fichiers sur le serveur
En ce qui concerne le dernier point, les fichiers envoyés sur le serveur sont forcément chiffrés, de sorte que personne ne pourra les lire sans la clé de déchiffrement. Clé connue uniquement en réunissant les différentes parties.
Un autre ajout majeur (et inédit) de Drycat est la possibilité, pour le chiffrement d'un fichier, de rendre une partie obligatoire. Ainsi, si le seuil est atteint sans que toutes les parties obligatoires ne soient rentrées, le déchiffrement sera invalide.
Pour le moment, il faut simplement être enregistré sur le serveur pour pouvoir y téléverser des fichiers, avec certaines restrictions (taille du fichier, durée de vie du fichier). La fonctionnalité d'envoi par mail étant réservé à des comptes payants. Cette partie payante sera mis en œuvre selon la demande des utilisateurs car cela nécessite la création d'une société. Mais le but premier est que les gens puissent s'amuser en toute autonomie.