BIIIIIIIIIIIP BIIIIIIIIIIP BIIIIIIIIIIIP. C'est ainsi que commence la journée. Ce bruit énervant du réveil sonnant peu après 6h et qui nous arrache de notre sommeil sans crier garde. Pour ma part, je suis également sensible à la lumière du jour qui filtre à travers les volets, elle suffit à me réveiller en été (dommage pour les grasses mat'). Je dois dire que cette méthode est beaucoup plus agréable que le réveil classique !
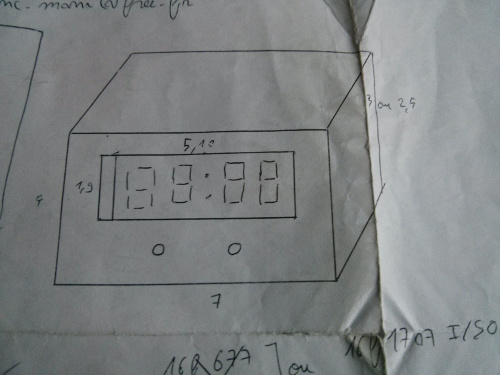
Il y a presque 10 mois maintenant, je me suis mis en tête de réaliser un réveil lumineux, pour plusieurs raisons :
- Jeter à la poubelle mon téléphone portable (en tant que réveil)
- Ceux du marché ne me conviennent pas et sont hors de prix
- Le challenge intellectuel
Il faut dire qu'avec l'avènement des imprimantes 3D et consort, le champ des possibilités offertes au particulier explose. Après une première étude, je me rends compte que la partie mécanique risque de ne pas être évidente et je décide de revoir mes objectifs. Justement, j'ai besoin d'un chronomètre pour la cuisine (donc une version plus simple d'une horloge). Car, quoi de plus embêtant que d'utiliser un téléphone portable, fragile, jamais au bon endroit et gros consommateur de batterie ? L'horloge du salon n'étant, elle, pas assez précise.
J'ai la chance de travailler à Sophia-Antipolis qui possède son fablab : SoFab. Mieux encore, il se situe dans mon ancienne école d'ingénieur ! Je vais donc y faire un tour. Ma première impression est plutôt négative. Si le fablab possède bel et bien de super machines (imprimantes 3D, découpeuse laser, outillage classique, outillage électronique), il lui manque une composante fondamentale (pour moi) : la partie électronique. La seule chose que l'on me propose pour le cœur du système est une base Arduino, ce qui ne rentre pas dans mes contraintes (voir plus bas), sachant que je ne veux pas réaliser un prototype, mais un produit fini.
Un peu déçu, je rentre chez moi et continue mes recherches. J'ai la chance de travailler à Sophia-Antipolis où, fait de plus en plus rare, il existe un club de robotique : PoBot. Enfin des gars qui tâtent du transistor ! Ce n'est jamais évident d'arriver dans un club en cours de route. Il y a en cette période beaucoup de jeunes (10-15 ans) qui font des petits projets et apprennent ainsi les bases de l'électronique (la plupart en savent plus que moi). Au milieu de ce cercle plutôt bruyant, je tombe sur Frédéric M. qui deviendra mon mentor au club. Je lui expose mes contraintes :
- Contrainte de taille : environ 4cmx7cm
- Carte simple couche
- Microcontrôleur PIC
- Afficheur 7 segments multiplexé HDSP-B03E
- Fournisseur farnell
- Utilisation de piles rechargeables au format standard (AA ou AAA)
- Consommation la plus faible possible
Si le schéma de base apparaît assez simple (d'un point de vue électronique), ajouter ces contraintes relève le niveau d'un cran. Pour se faire, Frédéric va réaliser une carte sur laquelle nous allons souder des composants CMS (Composant Monté en Surface), donc non traversant et avec une taille réduite (il faut avoir de bons yeux). On s'autorisera quand même quelques straps sur la face arrière. Néanmoins, ce sera une première pour le club !
Après une première analyse des différentes datasheets (notamment celle du PIC), le schéma de base est posé :
Quartz 32.768kHz <-> PIC <-> résistances <-> Afficheur
Pour des raisons de facilité, je me lance dans l'apprentissage du logiciel eagle PCB afin de dessiner la carte (d'un point de vue schématique et routage). J'aurais pu également utiliser le logiciel open source kicad. Nous sommes début avril. Après de multiples échanges, tant au club que par mail et 10 versions suivantes, nous obtenons le schéma final. Je suis tombé dans à peu près tous les pièges d'eagle, en plus de m'être trompé sur le connecteur des piles (problème de commande). Au passage, le schéma a évolué. Des pattes du PIC sont libres, il a donc été décidé de rajouter une photorésistance afin d'évaluer la luminosité ambiante pour adapter l'intensité de l'afficheur (donc diminuer la consommation et obtenir un affichage plus agréable), mais aussi (grosse astuce) de réutiliser les pattes dédiées au connecteur ICSP comme source d'entrée partagée.
Le matériel est commandé. Je prends des résistances de différentes valeurs pour m'adapter au mieux lors du test en conditions réelles : l'évaluation réelle des composants reçus. Avant de lancer la production de la carte je réalise (dans le doute) un premier prototype sur une breadboard. Tout semble tenir la route, sauf que l'intensité du 7 segments est assez faible. Voici venu l'heure de la rencontre avec le multimètre ! Visiblement, le PIC a du mal à sortir les 25mA annoncés lorsqu'il est alimenté en 3V... Si on ajoute le mutliplexage, ce n'est pas 25mA, mais 40mA qu'il faudrait délivrer afin d'avoir un affichage convenable.

Deux solutions s'offrent à nous : utiliser des transistors sur chaque patte du 7 segments ou prendre un driver de LED. La première solution est un enfer niveau routage (trop de croisements), impossible à réaliser proprement en simple couche. J'opte donc pour la seconde. Le composant utilisé étant assez gourmand (1V), il faudra rajouter une pile de plus. Le schéma évolue et prend de l'embonpoint mais, l'expérience aidant, la démarche est plus rapide.
Vient finalement l'heure de la réalisation de la carte. Ça y est, elle est entre mes mains, complètement nue. Elle est impeccable. Il faudra néanmoins gratter un peu les pistes pour augmenter les empreintes des composants les plus fins afin de faciliter le soudage. La perceuse n'est pas très bien maintenue dans l'axe, 3 mèches y passent, deux trous sont en dehors de leur position prévue. Je soude les gros composants en premier (l'afficheur, le connecteur ICSP) avec la méthode classique à l'étain. L'afficheur est relevé afin de compenser la profondeur des boutons. Cela s'avérera pratique pour manipuler le circuit, mais cause quelques faux contacts de temps en temps. S'ensuit la partie délicate : les composants CMS. La technique est différente : on dépose une pâte sur la partie cuivrée, puis délicatement le composant, avant de chauffer le tout avec de l'air à 260°C afin que la pâte se transforme en soudure. D'abord les résistance qui sont un peu plus grosses, afin de se faire la main, puis le PIC et le driver, ce qui représente respectivement 20 et 18 pattes d'un demi millimètre et séparées entre elles par 1,27mm. Si l'opération est un peu longue, il n'y a pas eu de soucis particulier (sauf UN faux contact sur deux pattes du PIC). Le tout est vérifié au fur et à mesure avec le multimètre.

La partie logicielle a été développée en parallèle. Je n'ai pas rencontré de difficulté particulière concernant cet aspect. Il a fallu optimiser au maximum la taille du code (donc la rapidité d'exécution, surtout dans la routine d'interruption), ainsi que les accès mémoires. J'ai une tendance à privilégier les accès 32 bits alors que dans le cas d'un PIC, ce sont les accès 8 bits qui sont plus performants ! Finalement les PLLs sont configurées pour fonctionner à 4Mhz, le composant est un peu trop limite à 2Mhz (clignotements visibles dû au multiplexage). J'aurais aimé pouvoir réduire encore la fréquence à 512kHz !
Après avoir soudé le quartz, je programme un premier test pour calibrer les résistances en sortie du driver. Pas de chance, dans ma première commande (où le driver n'était pas prévu), je n'en avais pas pris des aussi faible, le projet prendra encore un peu de retard. La touche finale viendra avec la photorésistance que je soude en dernier (non testée dans la version initiale du logiciel). Pour des questions de routage, le connecteur ICSP n'est pas standard (les fils sont dans le désordre). J'ai eu une petite frayeur quand, une fois la photorésistance soudée, le PIC ne voulait plus se programmer : ai-je trop chauffé la carte lors de la soudure ? Y a-t-il eu un court-circuit ? Non, les fils ne sont simplement pas dans le bon ordre... Malgré tous les défauts qu'on peut attribuer au PIC, ce dernier est quand même d'une qualité de fabrication qui le rend très robuste (une inversion des bornes d'alimentation : même pas peur !). Finalement le voilà, le circuit fonctionne et réagit à l'appui des boutons, change d'intensité dans l'obscurité, que demander de plus ?

Que demander de plus ? Une boîte évidemment ! Ma première idée m'avait amené à une boîte carrée, simple, en bois. Parce que c'est un peu plus classe, elle ne sera plus en bois, mais en plastique transparent ce qui, au passage, sera plus pratique pour la photorésistance. Sauf que voilà... le circuit a un peu évolué, l'alimentation aussi. Je n'ai absolument pas pris en considération les aspects mécaniques lors de la conception et, les trous présents sur l'un et sur l'autre des deux circuits ne concordent pas ! Les dimensions sont quasi identiques, mais pas exactement (l'un est plus grand, l'autre plus large). Il va falloir se creuser un peu la tête pour assembler tout ça, sachant qu'il faudra pouvoir l'ouvrir régulièrement afin de recharger les piles. Pour se faire, retour chez SoFab !
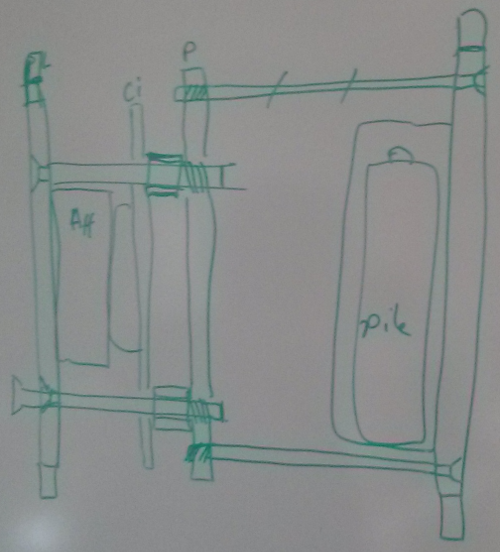
Frédéric a une bonne idée : coller les contours extérieurs de la boîte, puis utiliser une plaque intermédiaire afin de rendre solidaire la face arrière (avec les piles) et la face avant (avec la carte électronique). Le plastique utilisé sera du PMMA coulé 3mm, malheureusement non disponible chez les distributeurs grand public (Castorama, Bricorama...). Sofab en a en stock. La conception de la boîte est plutôt rapide. Pour se faire, j'utilise (comme conseillé par Marc, le responsable du fablab) le logiciel de dessin vectoriel inkscape. Je dessine les six faces en mode créneaux, ajoute les trous et un petit texte histoire de. Ce fichier sera ingurgité par la découpeuse laser. La première boîte est conforme aux attentes, si ce n'est la plaque intermédiaire qui ne possède pas assez de marge pour faire passer facilement les fils d'alimentation ainsi que quelques rayures (la plaque utilisée est un peu abîmée). Le taraudage à la main est quant-à lui fastidieux. Mais j'ai pu réaliser le tout avec des chutes gracieusement offertes part SoFab. Vient la phase de collage. Première erreur : je colle la face avant (qui était censé tenir la pièce pendant le séchage). Rien de catastrophique à première vue, ce sera juste moins pratique à monter/démonter. Content de moi, je rentre à la maison.

Quelle horreur je découvre le lendemain. La colle utilisée était de l'acrylique ! Elle a attaqué le plastique, le résultat est debout, mais plus très transparent, surtout que cette colle a tendance à dégager des vapeurs et donc attaquer tout le plastique qui l'entoure. Heureusement que je n'avais pas inséré mon circuit ! Il faudra un second passage à la découpeuse (j'en profite pour réduire la taille de la plaque intermédiaire). Le connecteur des piles ayant été collé, je me vois contraint de le garder, je ne peux donc pas réduire la taille globale du boîtier (dans lequel j'ai pris des marges trop grandes). Collage avec une colle à UV cette fois. Le résultat est gros, un peu lourd mais satisfaisant. La partie soudure finale (celle de l'alimentation et des boutons) est elle aussi laborieuse (je ne suis pas encore totalement au point). Finalement, je réalise une dernière erreur : je tente de coller des aimants à l'intérieur du boîtier. D'une part, le résultat n'est pas suffisamment puissant pour adhérer (il aurait fallu les coller à l'extérieur) et d'autre part, les aimants débordent sur les jointures de la boîte, elle sera donc aérée !

Après 8 mois, le chrono voit enfin le jour. Autant dire que les coûts et le temps de développement ont été beaucoup plus important que ce qui était prévu au début ! Cela correspond en réalité au coût d'apprentissage (ou encore "ticket d'entrée"), et j'ai beaucoup appris ! Dans plein de domaines : électronique, mécanique et informatique (spécificités des microcontrôleur). Faire un projet équivalent ou plus complexe est beaucoup plus rapide à partir de maintenant, pour un résultat plus pertinent. Il faut dire que le travail effectif n'a finalement été que de quelques heures par semaine. Chaque étape ou revue rajoute une semaine de délai. Les allers-retours par mail pendant la semaine n'ont pas permit de compenser cela. Il reste deux points que j'ai grandement sous-estimé en début de projet : la gestion de l'alimentation (qui est critique) et la gestion de l'emballage (la boîte) même si, pour la seconde, il était difficile pour moi d'avoir une connaissance des possibilités et des contraintes que pouvaient engendrer une conception mécanique alors que ces deux éléments sont à prendre en compte dès la phase de conception.
À table !!
PS : Je tiens à remercier toute l'équipe de Pobot et en particulier Frédéric M. pour tout le temps qu'il m'a accordé.