Upgrade Cubox-i Linux kernel
In the beginning of October, Debian pushed a security update for libssl. After installing it, all new SSH connections fails with message (even with correct password, or root login) :
fatal: privsep_preauth: preauth child terminated by signal 31
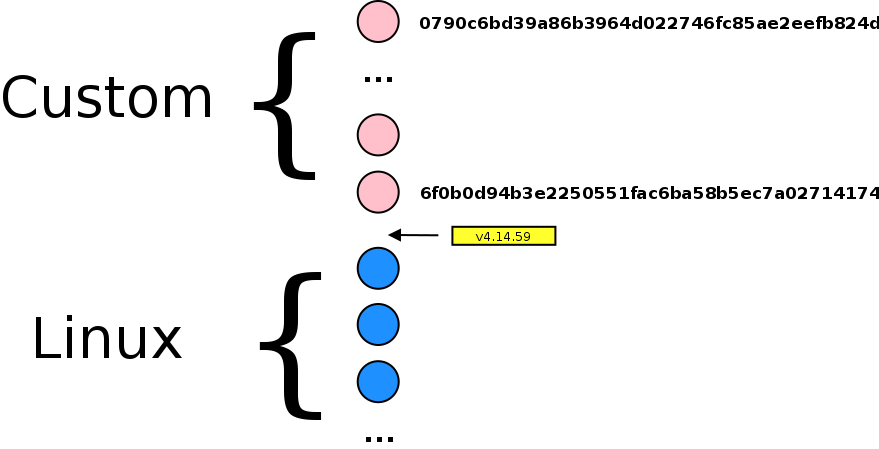
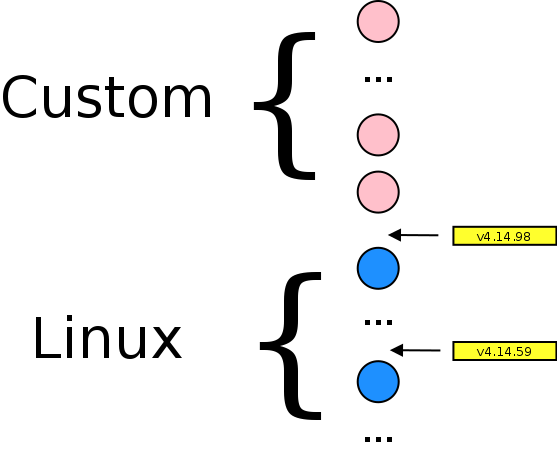
After searching on Internet, I found that nor SSH, nor libssl were in cause. It was due to an old kernel. I was running Linux 3.14 kernel because http://repo.r00t.website is not maintained.
Fortunately, Solid Run still maintains Linux kernel source tree on Github. Next instructions are based on this page.
First, mount Cubox-i filesystem from SDcard (assume it's in /mnt/cubox).
At startup, uBoot is configured to load zImage and dtb/$dtb_file. zImage is a symbolic link allowing us to have multiple kernel in /boot, let's do the same for dtb directory :
cd /mnt/cubox
cd boot
sudo mv dtb/ 3.4.14
sudo mkdir dtbs
sudo mv 3.4.14 dtbs
sudo ln -s dtbs/3.4.14/ dtb
Next, kernel compilation. The linked page suggest to do a git clone which is very big (~3GB), I suggest to download a snapshot from Github. Now, we'll follows Solid Run instructions :
sudo apt install crossbuild-essential-armhf
cd linux_sources
export CROSS_COMPILE=arm-linux-gnueabihf-
export ARCH=arm
make imx_v7_cbi_hb_defconfig
make -j4 zImage dtbs modules
Then, install compiled files :
export INSTALL_PATH=$PWD/linux_install
export INSTALL_MOD_PATH=$PWD/modules_install
mkdir linux_install
make install modules_install dtbs_install
cp arch/arm/boot/zImage linux_install/vmlinuz-4.9.124
sudo cp -r linux_install/* /mnt/cubox/boot/
sudo cp -r modules_install/lib/modules/4.9.124/ /mnt/cubox/lib/modules/
Linux creates an image compressed with lzop which not seems to be supported by my version of uBoot, so we need to manually copy created zImage.
Modules installation can be done in one line :
sudo make modules_install INSTALL_MOD_PATH=/mnt/cubox/
Optionally, you can export headers :
sudo make headers_install INSTALL_HDR_PATH=/mnt/cubox/usr/local/include
Switch kernel
cd /mnt/cubox
sudo rm dtb
sudo ln -s dtbs/4.9.124/ dtb
sudo rm zImage
sudo ln -s vmlinuz-4.9.124 zImage
sync
Unmount and unplug SDcard. Power up. It should now run new Linux kernel !
Solid Run also have a repository for a Debian package for kernel, but for now I didn't saw any binary repository available on Internet.
Warning, Github kernel make my server crash a lot of time due to an error in ext4/fs driver. I compiled a vanilla kernel, from linux-4.19.y branch (same as Debian stable one). Use the same instructions for compilation (just add dtbs_install to make install command). My .config is available here. I didn't test HDMI, Bluetooth nor IR (red LED is off). Last thing : root partition is now on /dev/mmcblk1p1, don't forget to update kernel command line !
Enabling serial console
The serial console seems to not work anymore. To enable it, first edit /etc/inittab and add at then end :
1:2345:respawn:/sbin/getty -L ttymxc0 115200 vt100
Then, we need to enable getty with SystemD to have login prompt at startup :
sudo systemctl enable "getty@ttymxc0"
Finally, we need to update kernel command line. Edit /boot/boot.cmd and put :
consoleconsole=ttymxc0,115200n8
Build boot.scr from boot.cmd, documentation here:
mkimage -C none -A arm -T script -d boot.cmd boot.scr
sync