
IWLA 0.3
Thursday, 14 April 2016
|
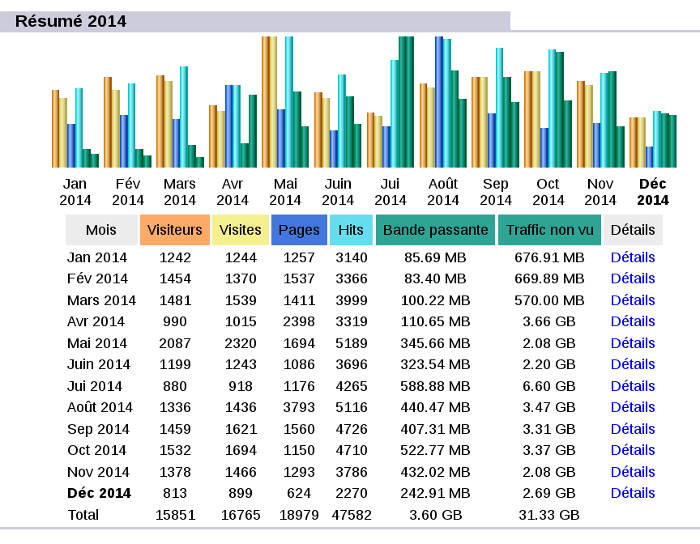
Bientôt un an depuis la version précédente d'IWLA (mon analyseurs de statistiques web écrit en Python) et, sans m'en rendre compte, il y a des tas de nouveautés ! Au menu:
- Mise en lumière des différences (par rapport à la dernière analyse) pour les mots clés ainsi que les fichiers téléchargés
- Rappel du résumé annuel dans les statistiques mensuelles
- Ajout de la durée de l'analyse
- Détection des navigateurs
- Détection des systèmes d'exploitations
- Détection des pays (grâce à iptogeo)
- Détection des clientS RSS
- Statistiques détaillées pour un/des visiteur(s) particuliers
- Possibilité de mettre à jour des configurationS par rapport à celles par défauts (sans écrasement) avec le suffixe "_append"
- Statistiques par heures
- Possibilité de spécifier plusieurs fichiers à analyser
- Support des fichiers compressés (.gz)
- Possibilité de ne pas compresser la base de données (option -z)
- Possibilité de spécifier ses propres moteurs de recherche
- Requêtes DNS inversés pour les clientS RSS
Quelques bugs ont été corrigés :
- Le dernier jour du mois n'était pas analysé
- Les pages accédées à la même seconde n'étaient pas analysées
Comme quoi, un logiciel "stable" n'existe pas. Je suis plutôt content de cette version qui est vraiment complète et avec des fonctionnalités non présentes dans AWStats ! Cela tient surtout en la modularité de l'architecture qui, certes, réduit un peu les performances, mais offre une grande souplesse dans l'écriture de modules (filtres).

