Virtual gift card in javascript
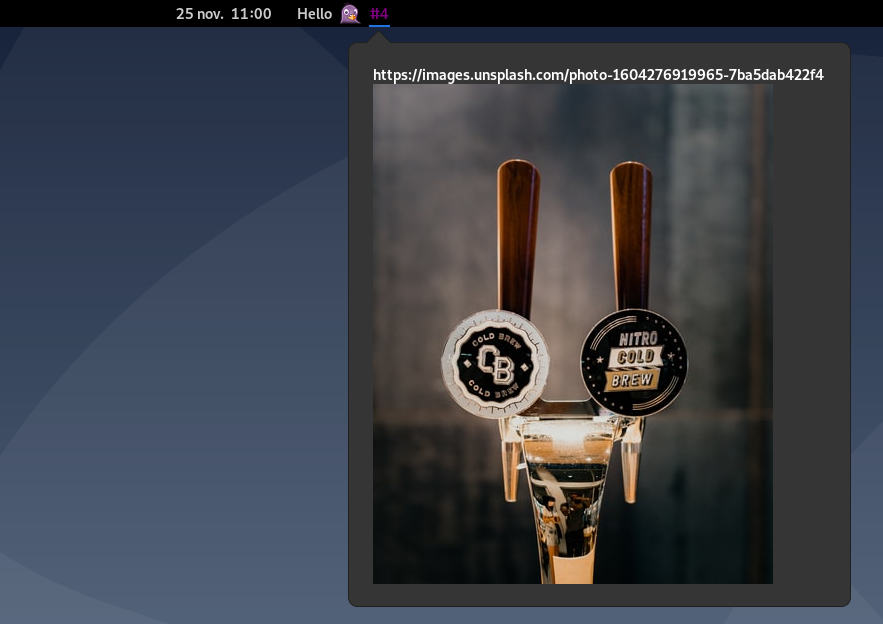
For a birthday I wanted to offer a gift card (something to buy online or later). As I don't have a printer, I decided to create a simple web page containing this card. The address has to be flashed by a Qr Code. But, instead of directly display the gift, I wanted to have something that the person has to discover progressively.
With a little bit of javascript and thanks to HTML5 Canvas API, we can do it easily ! The idea is to create a canvas and then fill the blurred gift or a gift paper. When the person click and drag the mouse over the card, it progressively draw the clear gift card.
Here, I hardcoded some values, but it's possible to get them from image details and do it fully dynamic (Canvas API allows to scale drawn pictures in drawImage() method). Some parts of the code is just a copy/paste from Internet (sorry for copyright, I didn't save the link).
Or the same image with a gift paper :
Javascript source code :
<center>
<canvas id="canvas" width="400" height="200" style="cursor:url(cursor32.png), auto ;">
</canvas>
</center>
<script>
var canvas = document.getElementById('canvas');
var ctx = canvas.getContext('2d');
var rect = {};
var drag = false;
var imageObj = null, image2Obj = null;
function init() {
imageObj = new Image();
// Gift paper version
imageObj.onload = function () { ctx.drawImage(imageObj, 0, 0); };
imageObj.src = 'paper.jpg';
// Blur version
imageObj.onload = function () { ctx.filter = 'blur(15px)'; ctx.drawImage(imageObj, 0, 0); ctx.filter = 'none'; };
imageObj.src = 'gift.jpg';
// Next
image2Obj = new Image();
image2Obj.src = 'gift.jpg';
canvas.addEventListener('mousedown', mouseDown, false);
canvas.addEventListener('mouseup', mouseUp, false);
canvas.addEventListener('mousemove', mouseMove, false);
canvas.addEventListener('touchstart', touchStart, false);
canvas.addEventListener('touchmove', touchMove, false);
}
function drawClearImage(x, y)
{
var canvasRect = canvas.getBoundingClientRect();
rect.startX = x - canvasRect.left - 5;
rect.startY = y - canvasRect.top - 5;
if (rect.startX < 0) rect.startX = 0;
if (rect.startY < 0) rect.startY = 0;
ctx.drawImage(image2Obj, rect.startX, rect.startY, 40, 40, rect.startX, rect.startY, 40, 40);
}
function mouseDown(e) {
drag = true;
drawClearImage(e.clientX, e.clientY);
}
function mouseUp(e) { drag = false; }
function mouseMove(e) {
if (drag)
drawClearImage(e.clientX, e.clientY);
}
function drawClearImageForTouch(x, y)
{
var canvasRect = canvas.getBoundingClientRect();
rect.startX = x - canvasRect.left - 60;
rect.startY = y - canvasRect.top - 60;
if (rect.startX < 0) rect.startX = 0;
if (rect.startY < 0) rect.startY = 0;
ctx.drawImage(image2Obj, rect.startX, rect.startY, 120, 120, rect.startX, rect.startY, 120, 120);
}
function touchStart(e) {
for (var i=0; i<e.changedTouches.length; i++)
drawClearImage(e.changedTouches[i].clientX, e.changedTouches[i].clientY);
}
function touchMove(e) {
for (var i=0; i<e.changedTouches.length; i++)
drawClearImage(e.changedTouches[i].clientX, e.changedTouches[i].clientY);
}
//
init();
</script>