Git: keep your commits in top of a branch
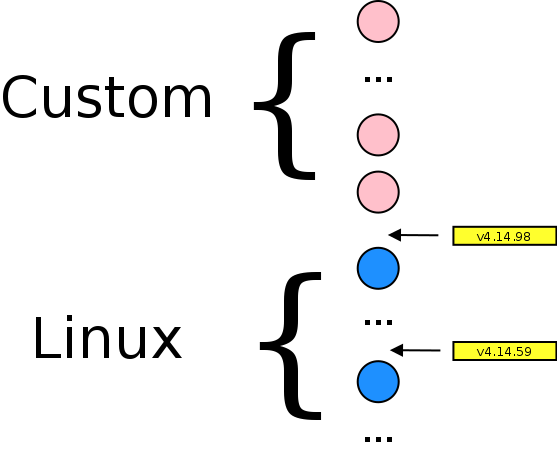
Today we'll play a bit with Git. At work, we make some products that uses customized Linux kernel. Once deployed, this kernel is not often updated, so we chose to be based on LTS (Long Term Support) kernels. This gives us staibility and not so many rebase to do. Unfortunately, kernel gets security patches that we must include into our development.
But, to keep clear history, we want to have all our commits in top of the vanilla branch. Plus, having this schema helps to extract all customs patches for Yocto or other build system.
For our case, history needs to be rewrote in a non trivial way.
We currently work with version v4.14.59, but nowaday, kernel.org has submitted revision v4.14.98. Lets says that we have made the following commits
6f0b0d94b3e2250551fac6ba58b5ec7a02714174 --> 0790c6bd39a86b3964d022746fc85ae2eefb824d
after tag v4.14.59. So, we have something like this :
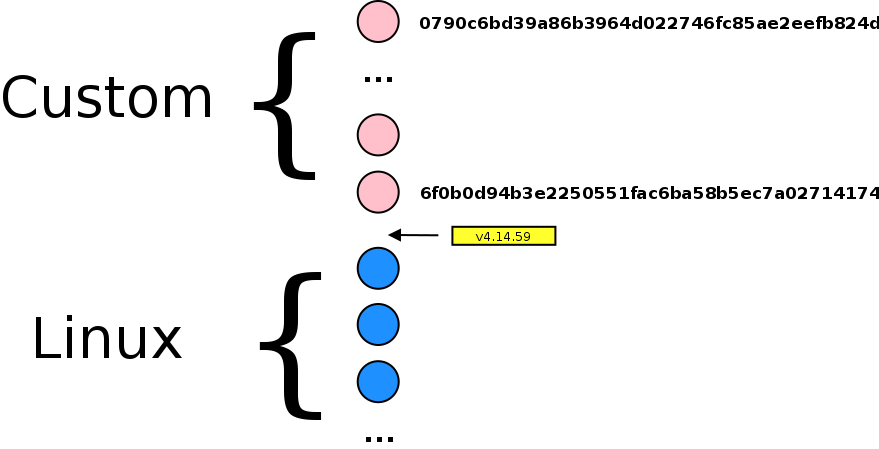
In our remotes we have :
- upstream --> points to kernel.org
- origin --> internal copy of kernel.org
Our branches are :
- linux-4.14.y -> upstream/linux-4.14.y (LTS branch)
- linux-4.14.y-custom -> origin/linux-4.14.y-custom
First, we need to update LTS branch
git checkout linux-4.14.y
git pull upstream linux-4.14.y
git fetch --tags upstream
The trick here is to put the HEAD of our custom branch at the last tag without deleting our commits. So, we need to make a copy of this one.
git checkout linux-4.14.y-custom
git checkout -b linux-4.14.59-custom linux-4.14.y-custom
Then, cut the the HEAD and integrate vanilla work.
git reset --hard v4.14.59
git rebase linux-4.14.y
Finally, integrate back our commits.
git cherry-pick 6f0b0d94b3e2250551fac6ba58b5ec7a02714174 .. 0790c6bd39a86b3964d022746fc85ae2eefb824d
The work is almost finished, we still need tu update internal tags we made ! Unlike subversion, a tag in git is just a reference to a specific commit, so it's easy to manage and update. Even if it's a shared repository, we can change them because people that uses them are focused on our custom commits and not on the ones in vanilla branch. Here is a script that get all custom tags references and apply them to the cherry picked commits. An other strategy could be to postfix tags with the new kernel revision. It's up to you to decide what better fit your needs.
The script assume all our custom tags starts with "customXXX".
#!/bin/bash
TAGS_PREFIX="custom"
OLD_START="v4.14.59"
OLD_END="0790c6bd39a86b3964d022746fc85ae2eefb824d"
NEW_START="v4.14.98"
nb_commits=`git log --pretty=oneline $OLD_START..$OLD_END|wc -l`
for tag in `git tag -l $TAGS_PREFIX`; do
cur_commits=`git log --pretty=oneline $OLD_START..$tag|wc -l`
new_commit=`git log --pretty="format:%H" -n1 --skip=$(($nb_commits - $cur_commits)) $NEW_START..HEAD`
# git log --pretty=oneline -n1 $new_commit
git tag -d $tag
git tag $tag $new_commit
done
Last thing to do, is to sync with remote. We need to pull from origin because HEAD had a strange behavior :
git pull origin linux-4.14.y-custom
git push origin linux-4.14.y-custom
git push origin linux-4.14.59-custom # Optional
git push --force --tags origin
Force for pushing tags is not needed if the tags were not modified, but just created. Now, we can delete our copy branch or keep it into git. Don't delete it, if you want to keep your old tags references !
Final result :