On ne le répétera jamais assez : avoir un serveur chez soi, c'est cool. On est réellement maître de ses données, de ce qu'on publie, de ce qu'on héberge, etc. Mais, parce qu'il y a toujours un mais, cela ne va pas sans contraintes. La première étant le débit montant. Avec une offre fibre, ce n'en est plus un (l'ADSL suffit si les fichiers ne sont pas trop gros). La seconde est l'administration. C'est une réalité, même s'il y a beaucoup de choses pour nous faciliter la vie (des paquets tout faits dans votre distribution préférée, voire une distribution dédiée). La dernière étant la disponibilité/réplication.
Disponibilité et réplication sont des notions inter dépendantes : pour avoir la première, il faut qu'en cas de panne, un autre serveur puisse prendre le relais. Donc, il y a nécessité de faire de la réplication (distante de préférence) et d'avoir un mécanisme qui permet de basculer automatiquement de l'un à l'autre. C'est le point que nous allons aborder aujourd'hui.
Pour faire de la réplication, il n'y a pas de miracles : il faut deux serveurs physiques avec (au moins) deux disques durs indépendants. Pour ma part, j'ai, d'un côté mon nouveau joujou "Déméter" (Cubox i2ex) en serveur principal (maître), et de l'autre, mon vieux Sheevaplug ("Cybelle"). Il faut ajouter à cela, un parent, un ami ou un collègue qui accepte d'héberger l'esclave.
Si la procédure est valable (et même cruciale pour un serveur), s'en est de même pour nos données personnelles en tant que particulier. Les inondations qui ont touchés la Côte d'Azur n'en sont que le triste exemple. J'habite au troisième étage ? Les canalisations du quatrième peuvent exploser, un incendie peut se déclarer, je peux être victime d'un vol. Donc dupliquez, dupliquez, dupliquez !
OpenVPN
La première étape est de configurer un tunnel OpenVPN entre les deux machines. Outre l'aspect sécurité d'un tunnel chiffré, OpenVPN est surtout très utile pour communiquer via une adresse (privée virtuelle) unique. On s'abstrait ainsi des problèmes de changement d'adresse IP, de résolution de nom.
Dans notre cas, on reporte la responsabilité de la création du tunnel sur l'esclave qui doit connaître l'IP publique du serveur maître.
Il faut ensuite mettre en place une configuration quasi similaire sur le maître et l'esclave, ce qui nécessite des petits réglages pas toujours évidents (surtout la gestion des différences).
Réplication
En ce qui concerne la réplication à proprement parler, il faudra appliquer différentes méthodes selon le service cible.
Pour un serveur web, des fichiers, des mails, on utilisera rsync.
rsync -auz root@cybelle:/var/mail /var
Pour une base de données, on s'appuiera sur le modèle maître-esclave de MySQL (dans mon cas)/PostgreSql/MariaDB...
Astuce : j'utilise une authentification SSH par clé pour l'utilisateur root sur l'esclave, valable uniquement à travers le tunnel OpenVPN.
On peut ainsi configurer un cron afin que tout soit automatique :
#!/bin/bash
HOST=soutade.fr
function cybelle_not_here()
{
echo "Cybelle not here" | mail -s "Error" root@$HOST
exit 0
}
# OpenVPN tunnel conectivity check
ping -c 1 cybelle >/dev/null || cybelle_not_here
# Get emails from Cybelle
rsync -auz root@cybelle:/var/mail /var
# Delete retrieved emails on Cybelle
ssh root@cybelle 'find /var/mail -name "*cybelle*" -delete'
# Push local data
rsync -auz /var/www root@cybelle:/var
rsync -auz /var/projects root@cybelle:/var
rsync -auz /home/soutade/www root@cybelle:/home/soutade
Cybelle est référencée dans /etc/hosts via son adresse privée OpenVPN.
Attention toutefois : même avec une sauvegarde distante, il est NÉCESSAIRE d'en faire une locale. Encore mieux, si elle est réalisée sur un disque chiffré. On notera que lors de la réplication (quotidienne), je lance une commande directement sur l'esclave (pour effacer les mails dans le cas présent).
DNS Failover
Maintenant que nous avons deux serveurs configurés sur deux sites distants, on peut commencer les choses sérieuses : la défaillance d'un des deux (surtout le maître). La solution proposée ici est une solution de pauvre et n'est pas recommandée pour un usage professionnel.
Nous allons discuter du DNS Failover (basculement DNS). L'idée est, qu'en cas de défaillance du serveur principal (maître), l'entrée DNS (NB: qui gère la correspondance nom de domaine/IP) soit mise à jour vers le serveur de secours (esclave). Cette solution (de pauvre) a deux inconvénients majeurs qui sont :
- La mise à jour des serveurs DNS primaires est de l'ordre d'une demi-heure
- Les entrées DNS peuvent être encore dans le cache du client (donc non rafraîchies)
Dans l'idéal, il aurait fallu avoir de l'IP failover, c'est-à-dire qu'un serveur frontal se charge de rediriger le trafic vers la bonne destination (celle qui est encore en vie). Mais cela nécessite des infrastructures beaucoup trop onéreuses pour les petits particuliers que nous sommes.
Pour la mise en pratique, j'ai modifié le script de mise à jour de DNS de Gandi afin qu'il retourne 34 quand une entrée vient d'être modifiée (détection d'un changement d'IP). Il affiche désormais sur la sortie standard l'ancienne et la nouvelle IP.
Sur l'esclave, un script est exécuté toutes les dix minutes. Il est chargé de vérifier que le maître est toujours vivant. Si ce n'est pas le cas, il change l'entrée DNS vers son IP actuelle (il réalise le basculement) :
#!/bin/bash
HOST=soutade.fr
MASTER_ADDRESS="10.8.0.1"
ping -c 4 checkip.dyndns.com 2>/dev/null || exit 0 # No internet connexion at all
ping -c 4 $MASTER_ADDRESS 2>/dev/null && exit 0 # Master is up, ouf !
python /home/soutade/gandi.py || exit 0
echo `date` | mail -s "Fallback server (cybelle) activated" root@$HOST
Sur le maître, un autre script est exécuté toutes les dix minutes également :
#!/bin/bash
HOST=soutade.fr
vals=`python /home/soutade/gandi.py`
if [ $? -eq 34 ] ; then
old_ip=`echo $vals | cut -d' ' -f9`
new_ip=`echo $vals | cut -d' ' -f5`
ssh -oStrictHostKeyChecking=no root@${old_ip} "sed -i -e 's/^remote .*$/remote ${new_ip}/g' /etc/openvpn/cybelle.conf ; service openvp\
n restart"
echo `date` | mail -s "Master server (demeter) activated" root@$HOST
fi
Si le changement d'IP est effectif (changement d'IP au niveau FAI ou redémarrage du serveur), on va modifier la configuration OpenVPN de l'esclave avec notre nouvelle IP et relancer le service.
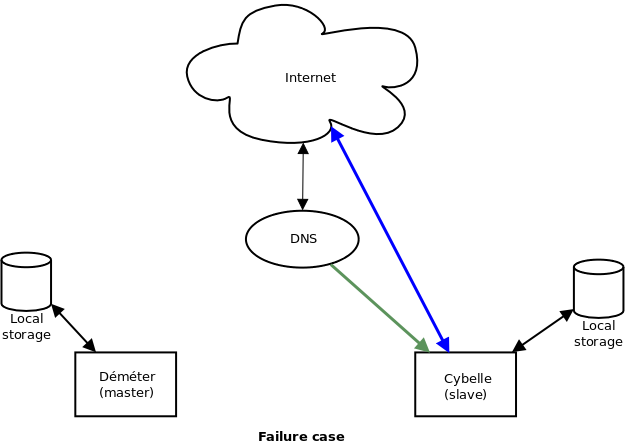
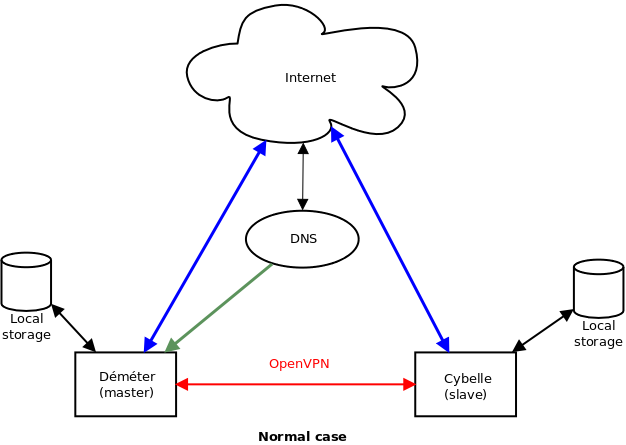
Un petit dessin pour bien visualiser les différentes situations :
Et en cas de défaillance du maître :