Coup de jeune pour mon Samsung r780
Mon Samsung r780 vient de fêter ses 4 ans. 4 ans en informatique, c'est entre 2 et 4 générations. Autant dire qu'on pourrait presque le voir comme obsolète. Pourtant, il n'a pas à rougir avec ses 4Go de RAM et son double cœur i5.
J'utilise clavier, souris et écran externe, l'intérieur est donc quasi neufs. La batterie aussi étant donné qu'elle n'est pas connectée. Néanmoins, avec le temps, il commence à chauffer énormément, en été comme en hiver provoquant des coupures de sécurité intempestives. Ce point là a été réglé avec une bombe d'air (5€-8€) : un coup à chaque entrée/sortie d'air disponible et c'est reparti ! Il faut cependant faire attention à bien garder la bombe à la verticale, sinon le gaz se liquéfie ! (obligé de passer un coup de séchoir avant la remise sous tension).

Autre point très Très TRÈS désagréable : le wifi. Sa gestion est catastrophique sous Linux. Deux murs fins suffisent pour avoir des déconnexions et un débit plus que réduit, alors que c'est à peu près correct sous Windows (et parfait via un smartphone)... Les derniers firmware de Debian (firmware-realtek dans non-free) semblent plus stables, mais le débit est toujours anémique.
Dernier goulot d'étranglement : le disque dur. À 5400tr/min, il fait pâle figure face à la dernière génération de SSD. Plusieurs options d'amélioration sont possibles :
- Acheter un disque 2.5" à 7200tr/min ou 10000tr/min : pas facile à trouver et consomme plus.
- Utiliser uniquement un SSD : la fiabilité d'un SSD dans le temps est encore à prouver. De plus, les gros SSD sont chers.
- Coupler un SSD (pour le système) avec un disque externe (pour les données) : ça prend de la place, une alimentation et un port USB (il n'en reste qu'un de libre), ou utiliser le port eSata.
- Coupler le disque avec un SSD en cache (intégré ou via une carte d'extension).
C'est la dernière solution que j'ai retenue. Les SSD au format ExpressCard ne sont quasiment plus fabriqués, j'ai donc opté pour la solution du SSHD (Seagate Momentus Laptop thin). Pour 60€, j'ai 500Go de disque (contre 640Go) avec un cache SSD de 8Go. Vous allez me dire : 8Go, c'est rien. Le minimum du minimum chez les SSD c'est 64Go. Certes, mais la vraie question est : est-ce que le système + les logiciels utilisés fréquemment tiennent dans ces 8Go ? Si on ne joue pas, la réponse est oui ! Bien sûr, les accès hors cache (directement depuis le disque) seront toujours aussi lent, mais 80% de mon utilisation passera par le cache SSD !
Pour préserver la licence de Windows, je choisis de faire un simple dd et là, c'est le drame : le nouveau disque est plus petit que l'ancien, donc la table des partitions a des références hors disque. Les mauvais BIOS bloqueront à cette étape. En passant par un live USB, je rétabli la table des partitions. Une fois passé cette longue copie, c'est au tour de la ré installation de GNU/Linux. La dernière fois, c'était il y a 4 ans, je ne suis donc pas forcément au fait de ce qui s'est passé depuis. Alors, quand on me parle de LVM, des VG, des PV et des LV, je suis complètement perdu !
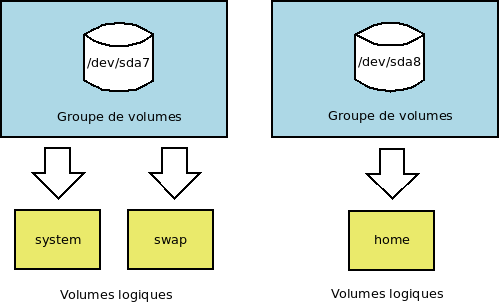
En fait LVM (Logical Volume Manager) n'a rien de très compliqué. Il permet d'abstraire des Volumes Physiques (PV) au sein de Groupes de Volumes (VG), pour en exporter un ou des Volumes Logiques (LV). C'est une "vieille" technologie héritée des serveurs qui, eux, manipulent de multiples espaces de stockage. On ne travaille plus qu'avec des volumes virtuels auxquels on peut ajouter/retirer des volumes physiques, faire des sauvegardes, faire du RAID... Les deux points qui m'intéressent particulièrement sont de 1) Chiffrer le volume et 2) Avoir du RAID. J'aurais aussi pu utiliser BTRFS qui intègre toutes ces fonctionnalités dans son cœur, mais je trouve plus élégant d'utiliser des couches séparées (stabilité, portabilité...). Pour l'anecdote, la première implémentation pour Linux date de 1998, mais sa popularité sur les machines personnelles est toute récente.
Chiffrer le disque est surtout utile en cas de perte/vol de l'ordinateur ou si on pratique des activités illégales et qu'on s'attend à recevoir la police pour dîner (ce qui n'est pas mon cas). Le RAID, quant à lui, permettra (dans l'avenir) de monter un serveur de sauvegarde en utilisant le SheevaPlug (ou une CuBox ?) ! En effet, les NAS sont hors de prix alors qu'on peut faire du RAID logiciel qui ne requiert pas un très gros débit pour juste de la sauvegarde.
Bref, je configure un groupe de volumes de 100Go qui va exporter les volumes logiques "system" et "swap" ainsi qu'un groupe de 250Go qui exportera home. "system" sera chiffré avec un mot de passe (au démarrage), "swap" avec une clé aléatoire et "home" avec une clé dans un fichier (/etc/luks-keys/home). Fichier qui sera lui même sauvegardé dans un autre endroit (après avoir été chiffré avec GPG) afin de pouvoir récupérer les données en cas de problème avec le volume "system". Cette configuration a l'avantage de ne demander le mot de passe qu'une seule fois tout en permettant de monter "home" depuis un autre système (si on possède le fichier de clés).
/boot sera (pour la première fois) une partition à part et non chiffrée (n'ayant pas de BIOS UEFI qui supporte une table des partitions GPT...). Petite blague : le noyau a pris de l'embonpoint et il est nécessaire d'augmenter la taille de la partition (200Mo), là où 20Mo suffisaient jadis.
Pour toutes les manipulations, il y a une procédure très bien expliquée sur le wiki d'ArchLinux. J'ai quand même dû rajouter l'option "rootdelay=1" à la ligne de commande au démarrage (il faudra vraiment que je règle le problème sans passer par ce bidouillage).
Dernier point : les systèmes de fichier utilisés. Comme on a un SSD, il faut éviter de trop écrire dans le cache, donc éviter autant que possible les systèmes de fichier journalisés, surtout sur /boot et / (qui risquent fortement de se retrouver dans le cache), ajouter les options "noatime" et "nodiratime" lors du montage des partitions, utiliser un maximum de parties du système en RAM (/tmp, /var...), ainsi que mettre le swappiness à 0 ("vm.swappiness = 0" dans /etc/sysctl.conf) afin de réduire au maximum l'utilisation du swap (qui risque aussi de se retrouver rapidement dans le cache SSD).
À vue de nez, l'utilisation courante semble deux à trois fois plus rapide (pari gagné). Je pense qu'on pourrait gagner encore sans LVM ni chiffrage (le noyau implémente un algorithme AES générique : pas d'accélération/optimisation matérielle). C'est aussi l'occasion de passer à Nouveau : il est un peu plus lent que les pilotes NVIDIA, mais il fait le job. Pour mon utilisation il suffit amplement.
Conclusion : pour ~70€, j'ai retrouvé un ordinateur qui tient tout à fait la route, au moins pour quelques années !